3 min read
消息队列 Overview
Message Queue 消息队列
场景
系统崩溃
存储行为服务的decouple

高并发
下单时的削峰

连路调用耗时长

Kafka
分布式的、分区的、多副本的日志提交服务,高吞吐下性能好:
- Producer batch zip
- Broker 顺序写,消息索引,零拷贝
- Consumer rebalance
基本使用

概念
Cluster
-
Topic: 逻辑队列,不同业务场景就是一个不同的topic
-
Partition: topic的分片,可以并发处理

Offset
partition 内的相对位置信息,消息的唯一id
Replica
Partition的副本,用来融灾
-
Leader 对外服务
-
Follower 异步拉取leader数据同步
-
ISR:从ISR中选取Leader Replica,当follower和leader差距较小时将follower加入ISR

架构
Cluster/Broker
图中 Broker 代表每一个kafka的节点,所有broker组成了一个cluster。
一共两个Topic,Topic1有两个partition,Topic2有1个,每个partition都是3replica。
Controller:有一个Broker同时是Controller,控制这个Cluster。
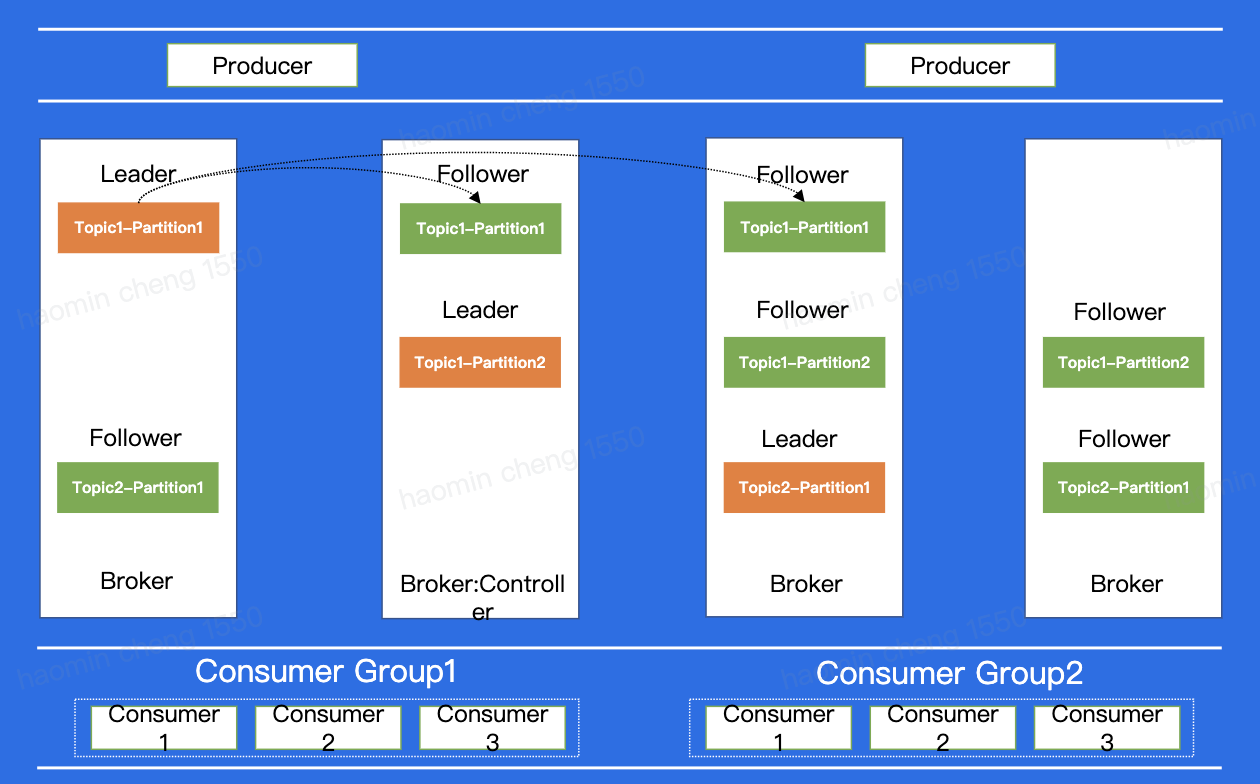
ZooKeeper
Cluster之上有一个ZooKeeper模块,存储Cluster的元数据,Controller计算好的数据都放到这里。

过程

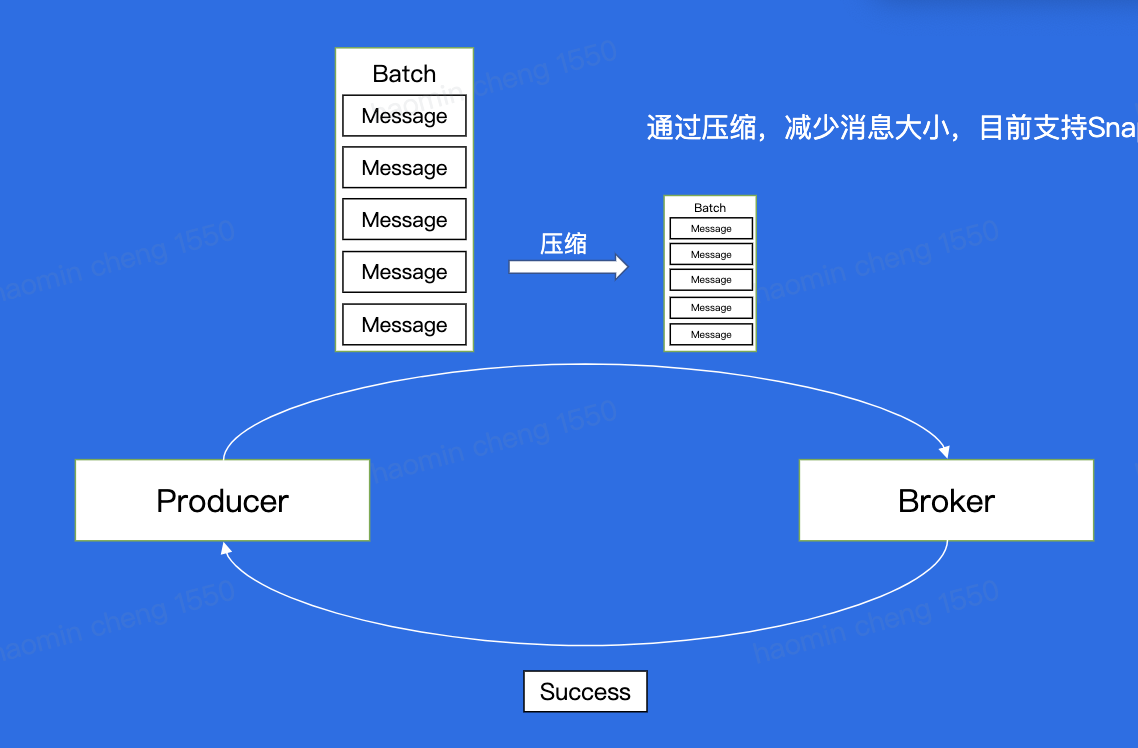
Producer
-
Batch:一次传输多个,减少IO
-
压缩:减少信息大小
Broker
顺序写消息文件存储

为顺序写方式,可以减少寻道时间:磁盘中,移动磁头找到磁道-》扇区-〉写入。
偏移量索引

数据拷贝
传统

零拷贝

consumer从broker中读取数据,从磁盘读到os后直接通过socket buffer网络发送。
Consumer
手动分配 Low level
Pros: 启动快
Cons: 如果新增consumer或者停用partition,需要停掉整个cluster进行修改。

自动分配 High level
选一个Broker作为Coordinator来帮助rebalance。

RocketMQ
对比Kafka:

同样是Producer, Consumer, Broker,只是partition-》message queue。

架构
特点:有一个nameserver提供轻量级服务发现和路由。

特性
事务场景


延迟发送

失败处理:消费重试和死信队列
